

Total System Latency: The Unspoken Constraint of Cloud-Based Inspection
When evaluating an AI visual inspection system, most engineers focus on detection accuracy, camera resolution, and throughput. The deployment architecture question, whether inference runs at the edge or in the cloud, often gets treated as a secondary decision. It should not. Where your AI model runs determines whether your inspection system can function at all under real production conditions.
This article breaks down the practical differences between edge and cloud AI inference for industrial inspection, covers the scenarios where each approach genuinely makes sense, and gives you a framework to make the right decision before you commit to a platform.
What Edge AI and Cloud AI Actually Mean in a Factory Context
In an industrial inspection deployment, the AI model needs to process images of parts moving along a production line and return a pass/fail decision fast enough to trigger a reject mechanism before the next part arrives. The question is where that image processing and decision-making happens.
Edge AI
Edge AI runs the inference model locally, on an industrial PC or embedded processor installed at the production line. The camera sends images to the local machine, the model runs on that hardware, and the decision is returned in milliseconds without any data leaving the facility. The line PLC receives the reject signal directly from the edge device.
Cloud AI
Cloud AI sends captured images to a remote server over the network, where the model runs on centralised compute infrastructure. The result is returned to the line controller over the same network connection. The inference itself may be faster on high-end cloud hardware, but the round-trip data transfer adds latency that is difficult to control.
The Latency Problem: What the Spec Sheet Leaves Out
Most cloud AI vendors quote model inference time, which is the time the model takes to process an image once it arrives at the server. This number can look very competitive, often under 50 milliseconds. What that figure does not include is network latency, which in a real factory environment can add anywhere from 20ms to 300ms depending on network congestion, distance to the cloud server, and packet loss.
On a high-speed production line running 600 parts per minute, each part occupies its inspection window for 100 milliseconds. If your total system latency, model inference plus network round trip, exceeds that window, you cannot reliably trigger the reject mechanism for the correct part. You will either miss rejects or false-reject the wrong part.
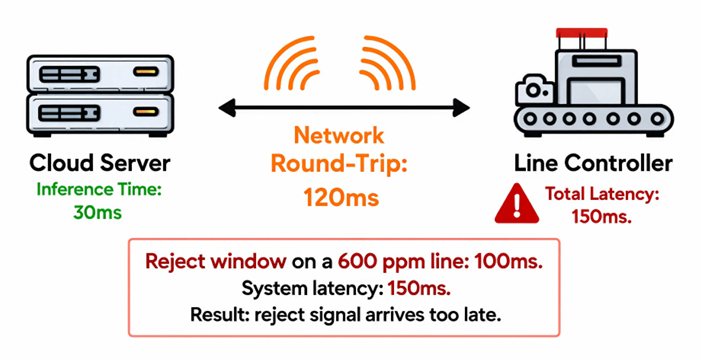
A cloud system with 30ms inference time and 120ms average network round-trip has a total latency of 150ms. On a 600 ppm line, that system cannot reliably reject defective parts. The spec sheet shows 30ms. The production floor sees 150ms.
Edge AI eliminates network latency from the equation entirely. With inference running locally on optimised hardware, total system latency can be held under 20ms regardless of what is happening on the factory network.
Four Factory Conditions Where Cloud AI Fails
Air-Gapped and Restricted Networks
Many manufacturing facilities, particularly in defence, pharma, and semiconductor production, operate on networks that are either air-gapped or heavily restricted for security and compliance reasons. Sending production images to a cloud server is not permitted. Edge AI is the only viable option in these environments.
High-Speed Lines
As covered above, any line running above roughly 200 parts per minute will expose the latency limitations of a cloud deployment. The faster the line, the smaller the reject window, and the more damaging unpredictable network latency becomes.
High Image Data Volume
A vision inspection system capturing full-resolution images at 400 ppm generates enormous data volumes. Transmitting those images to the cloud in real time requires bandwidth that most factory networks are not provisioned for. Compressing images before transmission degrades the data the model receives, which directly affects detection accuracy.
Connectivity Instability
Factory floors are not office environments. Network switches in production areas experience interference, cable faults, and congestion from other industrial equipment. A cloud-dependent inspection system that loses connectivity goes blind. An edge system keeps running regardless of what is happening on the wider network.
Where Cloud AI Genuinely Makes Sense
Cloud AI is not the wrong answer for every situation. There are specific production environments where it is the more practical choice.
- Low-speed manual assembly lines where cycle times are measured in seconds, not milliseconds, and network latency is not a constraint.
- Remote or distributed facilities where installing and maintaining edge hardware at multiple sites is more expensive than a centralised cloud subscription.
- Small manufacturers running limited SKUs with infrequent changeovers, where cloud model management is simpler than on-premise infrastructure.
- Applications where real-time rejection is not required, such as end-of-line sampling inspection or periodic audit checks.
- Organisations that need to aggregate inspection data across multiple global sites for centralised analytics without investing in site-level infrastructure.
The honest answer is that cloud AI is a better fit when production speed is low, connectivity is reliable, and centralised management is a priority. Edge AI is a better fit when speed is high, connectivity is unreliable, or data cannot leave the facility.
Total Cost of Ownership: The Comparison That Actually Matters
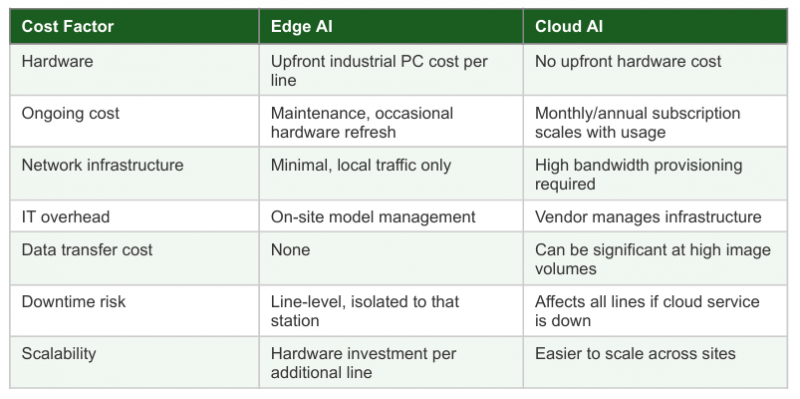
For a single high-speed line, edge AI typically reaches cost parity with cloud within 18 to 24 months when subscription fees and bandwidth costs are modelled honestly. For multi-line deployments at a single site, edge infrastructure costs are partially shared, improving the economics further. For multi-site deployments with low-speed lines, cloud can remain cost-competitive over the same period.
Five Questions to Ask Before Choosing Your Deployment Model
Before shortlisting vendors, answer these questions about your specific production environment:
- What is your line speed in parts per minute, and what is your reject window in milliseconds? If the window is under 200ms, edge AI is likely the only viable option.
- Is your facility network air-gapped, restricted, or subject to data sovereignty rules? If yes, cloud AI is off the table regardless of other factors.
- What is the image resolution and capture rate your inspection application requires?Calculate the bandwidth this would consume before assuming cloud connectivity is sufficient.
- How many lines or sites will you deploy across? The economics of edge vs cloud shift significantly as deployment scale changes.
- What happens to your production if the inspection system loses connectivity for 10 minutes? If the answer is that the line must stop, you need edge AI. If sampling can continue manually, cloud may be acceptable.
Fitting AI to the Reality of the Shop Floor
The edge vs cloud decision in AI industrial inspection is not a technology preference. It is an engineering constraint driven by your line speed, network environment, data volume, and risk tolerance for downtime. Vendors who offer only one deployment model are asking you to fit your production reality to their architecture rather than the other way around.
Evaluate deployment architecture before you evaluate features. A system with excellent detection accuracy that cannot reliably deliver reject signals on your line is not a solution. A system with slightly lower benchmark accuracy that runs reliably at the edge, stays online during network outages, and keeps latency under your cycle time is.
The spec sheet will tell you the inference time. Make sure you also know the total system latency under your actual network conditions before signing anything.
Author: Bhuvan Yadav
For more information: www.switchon.io


